Γιατί γίνεται όλο και πιο δύσκολο να αποδείξεις ότι δεν είσαι ρομπότ; Γιατί πρέπει να βρεις τις σκάλες, τα φανάρια, τα ποδήλατα και να στρίβεις γύρω γύρω φωτογραφίες;
Παλιά, ένα απλό κουτάκι «Δεν είμαι ρομπότ» αρκούσε. Σήμερα, όμως, τα CAPTCHA απαιτούν από τους χρήστες να εντοπίσουν φανάρια, ποδήλατα και σκάλες.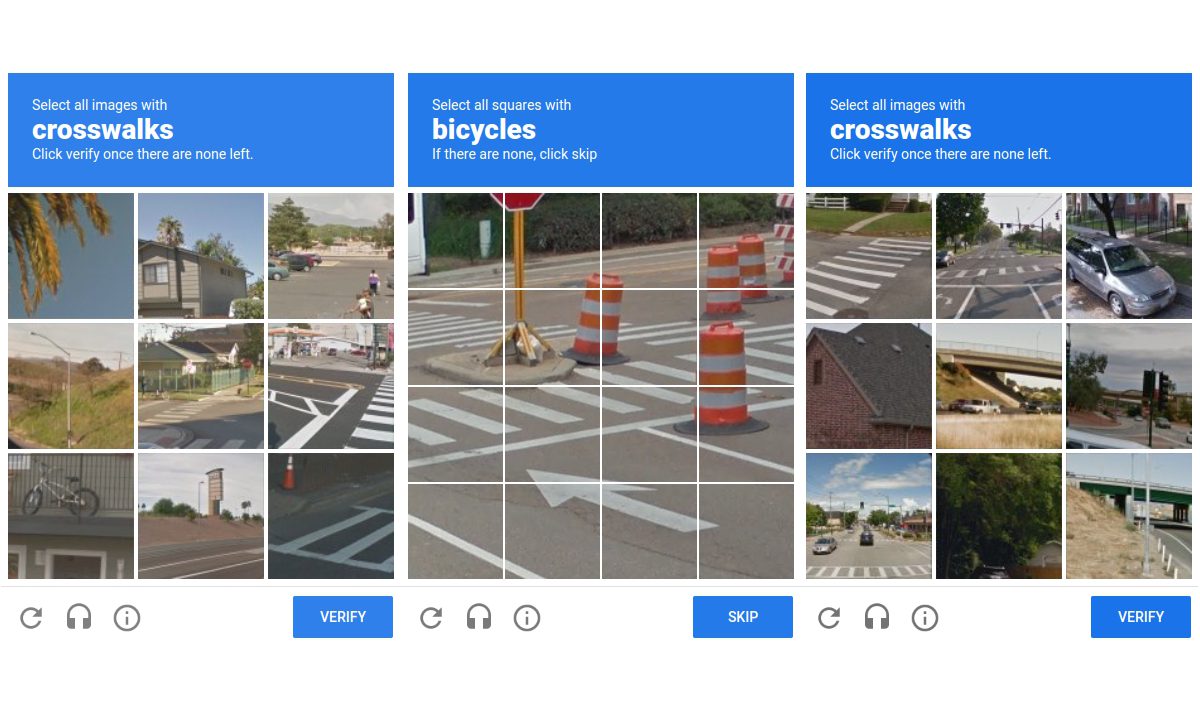
Το να αποδείξεις ότι είσαι άνθρωπος στο διαδίκτυο έχει γίνει μια παράξενη πρόκληση. Κάποτε, ένα απλό τσεκάρισμα του κουτιού «Δεν είμαι ρομπότ» αρκούσε για να περάσεις ένα CAPTCHA. Τώρα, όμως, πρέπει να εντοπίσεις σκάλες, φανάρια, ποδήλατα, να επιλέξεις εικόνες που περιέχουν λεωφορεία ή να περιστρέψεις φωτογραφίες στη σωστή κατεύθυνση. Γιατί όμως η διαδικασία αυτή γίνεται ολοένα και πιο περίπλοκη;
Η απάντηση βρίσκεται στην ίδια τη φύση των CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart). Αυτές οι δοκιμές σχεδιάστηκαν για να διαχωρίζουν τους ανθρώπους από τα αυτοματοποιημένα προγράμματα (bots). Όταν πρωτοεμφανίστηκαν στις αρχές της δεκαετίας του 2000, χρησιμοποιούσαν παραμορφωμένα γράμματα και αριθμούς που οι χρήστες έπρεπε να αποκωδικοποιήσουν. Με την πρόοδο της τεχνητής νοημοσύνης, όμως, οι αλγόριθμοι έγιναν ικανοί να διαβάζουν αυτές τις εικόνες πιο γρήγορα και με μεγαλύτερη ακρίβεια από τους ανθρώπους, καθιστώντας τα παραδοσιακά CAPTCHA αναποτελεσματικά.
Για να αντιμετωπίσει αυτό το πρόβλημα, η Google ανέπτυξε το reCAPTCHA, ένα εξελιγμένο σύστημα που προσαρμόζεται στις δυνατότητες των μηχανών. Οι πρώτες εκδόσεις του reCAPTCHA ζητούσαν από τους χρήστες να αποκρυπτογραφήσουν θολές λέξεις, αλλά καθώς οι αλγόριθμοι βελτιώθηκαν, η μέθοδος αυτή ξεπεράστηκε. Έτσι, η Google άρχισε να χρησιμοποιεί εικόνες του πραγματικού κόσμου από το Street View και άλλες πηγές, ζητώντας από τους ανθρώπους να αναγνωρίσουν αντικείμενα όπως φανάρια, διαβάσεις πεζών, σήματα κυκλοφορίας και ποδήλατα.
Η επιλογή αυτών των στοιχείων δεν είναι τυχαία. Οι εικόνες που χρησιμοποιούνται στα CAPTCHA συμβάλλουν στη βελτίωση της τεχνητής νοημοσύνης της Google, ειδικά στα αυτόνομα οχήματα. Όταν εκατομμύρια χρήστες επιλέγουν σωστά τις εικόνες που περιέχουν διαβάσεις πεζών ή φανάρια, η Google εκπαιδεύει τα συστήματά της να αναγνωρίζουν αυτά τα αντικείμενα στον πραγματικό κόσμο.
Ακόμα και το «Δεν είμαι ρομπότ» κουτάκι που φαίνεται απλό, στην πραγματικότητα δεν βασίζεται στην επιλογή του χρήστη, αλλά στο πώς κινείται το ποντίκι του και στο πώς αλληλεπιδρά με τη σελίδα. Αν το σύστημα υποψιαστεί ότι πρόκειται για bot, τότε εμφανίζει πρόσθετες δοκιμασίες, όπως η αναγνώριση εικόνων.
Το επόμενο στάδιο αυτής της τεχνολογίας είναι το Invisible reCAPTCHA, το οποίο δεν απαιτεί καμία ενέργεια από τον χρήστη. Αντί να ζητάει επιβεβαίωση, αναλύει τη συμπεριφορά του χρήστη στο παρασκήνιο, λαμβάνοντας υπόψη παράγοντες όπως το ιστορικό περιήγησης, την ταχύτητα πληκτρολόγησης και τη χρήση του ποντικιού. Αν το σύστημα είναι βέβαιο ότι ο χρήστης είναι άνθρωπος, η φόρμα εγκρίνεται αυτόματα, χωρίς καμία δοκιμασία.
Η συνεχής εξέλιξη των CAPTCHA είναι μια μάχη ανάμεσα στην ανθρώπινη νοημοσύνη και τις μηχανές. Όσο τα bots γίνονται εξυπνότερα, τόσο πιο δύσκολο γίνεται για εμάς να αποδείξουμε ότι είμαστε άνθρωποι.
Γρηγόρης Κεντητός
Γράφω για πράγματα που με συναρπάζουν, αλλά φροντίζω πάντα να τα ερευνώ σαν να τα μελετούσα για πρώτη φορά. Αναζητώ τη σύνδεση ανάμεσα στο χθες και το σήμερα, το ανθρώπινο μέσα στο ακαδημαϊκό, και τη γνώση που μπορεί να μεταφερθεί με τρόπο απλό, ακριβή και ζωντανό. Είτε πρόκειται για έναν αρχαίο πόλεμο είτε για ένα φαινόμενο της εποχής μας, στηρίζομαι πάντα σε πρωτογενές υλικό, πραγματικές πηγές και σοβαρή τεκμηρίωση. Θέλω κάθε κείμενο να αξίζει τον χρόνο του αναγνώστη — και τον δικό μου.








